Average number of wins for all teams shut out in the first 3 quarters of Week 3 preseason game (since 2000): 5.9 (N=15).
Just sayin'.
Monday, August 30, 2010
Tuesday, August 3, 2010
Preseason predictions - how to judge them?
Sigh. Once again, I'm writing a post which is basically a long response to a post of Brian Burke's. I'm starting to feel kinda bad because I don't harbor any resentment to him (or, really anyone else related to football statistics - it's just something I do completely for fun, usually during lunch).
But I really have trouble letting something go when it's wrong. And I've seen this mistake countless places, so here we go. There's a post here where he tries to compare the Football Outsiders preseason predictions to the results, and concludes that they're worthless, based on the Mean Absolute Error and the RMS Error. He claims that they're in fact, worse than just totally guessing.
He might be right that they're totally worthless. I have no idea. But I do know that his method of comparing them - using the mean and RMS - isn't good enough to say that, because they give a distribution of expected results, and that distribution isn't Gaussian. Plus he's also just using the mean prediction, which isn't all the information provided.
In fact, it's possible for one prediction to be better than another, even with a worse mean and RMS error.
First, imagine a season played 10,000 times. That would lead to some distribution of team wins - they win 10 so many times, 9 so many times, 8 so many times, etc. Divide by 10,000, and you get something that could be thought of as a probability distribution. It's not really, because the teams' distributions aren't independent. But pretend. It's the same thing that you're doing with mean/RMS anyway.
Now suppose you predict what that team's results are going to be. That gives you a second distribution. You expect so many times they'll win 10, so many times they'll win 9, etc.
So what's the best way to compare those distributions? Look at the mean and RMS of both of them? If the distributions are Gaussian (or "normal"), yes - because a Gaussian probability distribution is fully described by its mean and RMS (which turn out to be, in math-speak, its two moments). If they're non-Gaussian? No, most definitely not. Instead, the best way is a Kolmogorov-Smirnov test, also called a K-S test.
To describe: imagine the "underlying probability distribution" looks like this. This is probability of winning X games, from 0-16.

That's a flat distribution - you're equally likely to win 0 as 8 as 16. It's violently non-Gaussian. It also has a mean of 8 wins, and an RMS of 4.62.
Now let's imagine a Koko the Monkey prediction - you just say "8" every single time. This has a mean of 8 wins, and an RMS distribution of zero. That, obviously, looks like this:

Those two distributions look absolutely nothing alike. But if I draw from the "true" distribution, and predict with the "monkey" distribution, I'll get a mean absolute error of 0.0, and an RMS error of 4.62.
Now, here's the kicker. If my prediction was the true distribution, and I just use the mean (which is 8), I'll get a mean absolute error of (drum roll) - 0.0, and an RMS error of 4.62.
The problem, here, is that we didn't take into account the fact that the monkey distribution was predicting that it'll always be 8. And that's clearly wrong. But you could easily say "but at least it's right about the mean," right?
Nope. Now imagine someone trying to predict things here. They do a bunch of tests, and (wrongly) conclude that there's some information, but for the most part it's random - so they predict that the true distribution is a Gaussian distribution, with a mean of 4, and a width of 32. This looks like this:

It probably looks essentially flat to you ; there's a slight, slight excess around 4, and there are more 0-7 than 9-16 predictions. This results in a mean of 7.8, which means that the mean absolute error, if you used this distribution to predict things, would be 0.2. The RMS error would be a bit bigger than 4.62 (but not much).
So this distribution has a worse mean absolute error, and a worse RMS error, than Koko the Monkey's prediction. And yet, it has a better K-S test statistic (significantly better) than Koko the Monkey's prediction. It is, in fact, a much better guess as to the underlying distribution than Koko the Monkey's guess.
But isn't Koko the Monkey's prediction better? It's better in both RMS error and absolute error, right? No, absolutely not. If someone told you team A will win 8 games, guaranteed, and you believed them, you'd bet on an over-under of 7 games, wouldn't you? What about if someone told you they're just about as likely to win less than 7 as more than 7? Then you wouldn't.
Comparing mathematical predictions for football is always a little tough, especially because you only get one shot at it, and really, all 32 teams have different factors involved. So you really want to look at the ability of a prediction system to predict, say, a team when it changes quarterbacks, or changes coaches, separately than when you're just predicting effects from high-leverage regression to the mean.
But just looking at mean absolute error and RMS error is really, really simplistic. What you really care about is comparing the prediction to the result. The predictions have some distribution, and the results have some distribution, so the best way to compare them is a K-S test.
But I really have trouble letting something go when it's wrong. And I've seen this mistake countless places, so here we go. There's a post here where he tries to compare the Football Outsiders preseason predictions to the results, and concludes that they're worthless, based on the Mean Absolute Error and the RMS Error. He claims that they're in fact, worse than just totally guessing.
He might be right that they're totally worthless. I have no idea. But I do know that his method of comparing them - using the mean and RMS - isn't good enough to say that, because they give a distribution of expected results, and that distribution isn't Gaussian. Plus he's also just using the mean prediction, which isn't all the information provided.
In fact, it's possible for one prediction to be better than another, even with a worse mean and RMS error.
First, imagine a season played 10,000 times. That would lead to some distribution of team wins - they win 10 so many times, 9 so many times, 8 so many times, etc. Divide by 10,000, and you get something that could be thought of as a probability distribution. It's not really, because the teams' distributions aren't independent. But pretend. It's the same thing that you're doing with mean/RMS anyway.
Now suppose you predict what that team's results are going to be. That gives you a second distribution. You expect so many times they'll win 10, so many times they'll win 9, etc.
So what's the best way to compare those distributions? Look at the mean and RMS of both of them? If the distributions are Gaussian (or "normal"), yes - because a Gaussian probability distribution is fully described by its mean and RMS (which turn out to be, in math-speak, its two moments). If they're non-Gaussian? No, most definitely not. Instead, the best way is a Kolmogorov-Smirnov test, also called a K-S test.
To describe: imagine the "underlying probability distribution" looks like this. This is probability of winning X games, from 0-16.
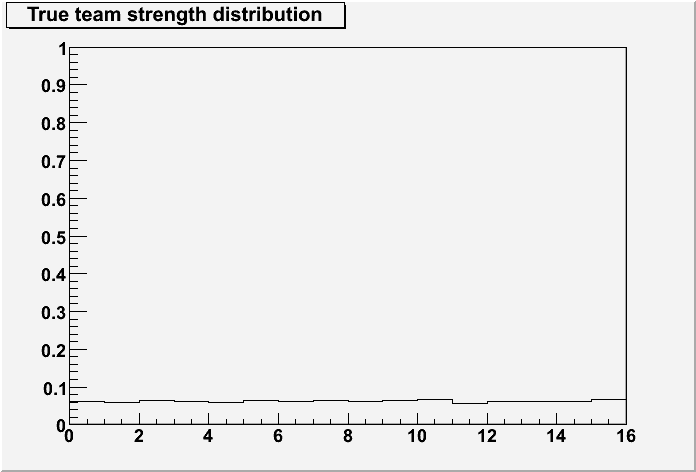
That's a flat distribution - you're equally likely to win 0 as 8 as 16. It's violently non-Gaussian. It also has a mean of 8 wins, and an RMS of 4.62.
Now let's imagine a Koko the Monkey prediction - you just say "8" every single time. This has a mean of 8 wins, and an RMS distribution of zero. That, obviously, looks like this:

Those two distributions look absolutely nothing alike. But if I draw from the "true" distribution, and predict with the "monkey" distribution, I'll get a mean absolute error of 0.0, and an RMS error of 4.62.
Now, here's the kicker. If my prediction was the true distribution, and I just use the mean (which is 8), I'll get a mean absolute error of (drum roll) - 0.0, and an RMS error of 4.62.
The problem, here, is that we didn't take into account the fact that the monkey distribution was predicting that it'll always be 8. And that's clearly wrong. But you could easily say "but at least it's right about the mean," right?
Nope. Now imagine someone trying to predict things here. They do a bunch of tests, and (wrongly) conclude that there's some information, but for the most part it's random - so they predict that the true distribution is a Gaussian distribution, with a mean of 4, and a width of 32. This looks like this:

It probably looks essentially flat to you ; there's a slight, slight excess around 4, and there are more 0-7 than 9-16 predictions. This results in a mean of 7.8, which means that the mean absolute error, if you used this distribution to predict things, would be 0.2. The RMS error would be a bit bigger than 4.62 (but not much).
So this distribution has a worse mean absolute error, and a worse RMS error, than Koko the Monkey's prediction. And yet, it has a better K-S test statistic (significantly better) than Koko the Monkey's prediction. It is, in fact, a much better guess as to the underlying distribution than Koko the Monkey's guess.
But isn't Koko the Monkey's prediction better? It's better in both RMS error and absolute error, right? No, absolutely not. If someone told you team A will win 8 games, guaranteed, and you believed them, you'd bet on an over-under of 7 games, wouldn't you? What about if someone told you they're just about as likely to win less than 7 as more than 7? Then you wouldn't.
Comparing mathematical predictions for football is always a little tough, especially because you only get one shot at it, and really, all 32 teams have different factors involved. So you really want to look at the ability of a prediction system to predict, say, a team when it changes quarterbacks, or changes coaches, separately than when you're just predicting effects from high-leverage regression to the mean.
But just looking at mean absolute error and RMS error is really, really simplistic. What you really care about is comparing the prediction to the result. The predictions have some distribution, and the results have some distribution, so the best way to compare them is a K-S test.
Monday, June 14, 2010
Decision theory in football, and the question of risk
Part 1: Introduction
You may have seen a few websites talking about decisions by coaches recently - Bill Belichick's famous 'go for it on 4th down' failure pretty much pushed them into the mainstream visibility, but footballcommentary.com has been around for a while, while Advanced NFL Stats is more recent.
The entire idea behind both of those websites is simple: you have a decision between two or more options - we'll stick with 2, and call them A and B. Figure out all possible outcomes of A, and average them. Figure out all possible outcomes of B, and average them. If A's average outcome is better than B's average outcome, choose A, otherwise choose B.
Pretty simple, huh?
One problem: it ignores the distribution of the outcomes of B and A - that is, it ignores the risk involved. All in all, the average expected value will tend to win out in the long run. But games, seasons, and coaches' careers aren't infinite - which means it's not really simple enough to ask "what's the best average expected outcome?" You really have to analyze the risk involved somehow.
Almost all of the 'decision questions' in football involve risky decisions vs. safe decisions. Should the coach go for it on 4th and 2 or punt? Punts are relatively safe - it's safe to simplify things and say that a punt is always better than a failed 4th down conversion.
That means that you have two choices: take a safe option (punting) and gain a little, or risk that to gain a lot.
Brian at AdvancedNFLStats basically puts it this way: going for it is a 60% chance of having a 100% chance to win the game, and a 40% chance of having a 53% chance of winning the game. Punting results in a 70% chance to win the game.
So, let's rescale things to make it more obvious, and subtract 53% (the lowest win chance) from all numbers. The question, then, is: "should I take a guaranteed 17% improvement in win probability, or go for a 60% chance at a 47% improvement?" Obviously the "expected value" choice is to go for it. However, look at the two positive outcomes: in one case, you win 100% of the time, and in the other case, you win 70% of the time. Those are both pretty good positions to be in. Now look at the negative outcome: you win with 53% chance. Basically a coin flip.
It's reasonable to believe that a coach might look at that and say "you know, winning 70% of the time and ~100% of the time aren't that different, but winning 53% of the time sucks." Let's put it a different way: winning 70% of the time gets you 11 wins, and good freaking chance you're in the playoffs. Winning 100% of the time? OK, you're obviously in the playoffs. Winning 53% of the time? 8 wins and you're going home.
What I'm suggesting is that coaches might view their improving odds with diminishing returns, and not see that much of a difference between 70% and 100%. Football is a low-scoring sport, with just a few high-leverage plays - taking the 'safe' decision too often isn't all that crazy.
The interesting thing - to me, at least - is that you could try to figure out exactly how coaches *do* view winning percentages. How valuable is it to a coach to move his winning percentage from 90% to 95%? What about from 50% to 55%? It's safe to say that even though they're equivalent changes, I doubt most coaches would care much about the former if there was much risk involved. Can we do this?
Easy - instead of starting off with the assumption that coaches don't know the percentages, and are simply making ill-informed decisions, assume that they *do* know the percentages, and try to find a function which rescales the winning percentages (u(WP%)) which makes the 'safe' decision better (i.e. the one they actually take).
That function - the u(WP%)? It's usually called a utility function.
As it turns out, it doesn't take a lot to do this. I'll show that in a future post, using Belichick's decision, which is pretty ideal for this.
You may have seen a few websites talking about decisions by coaches recently - Bill Belichick's famous 'go for it on 4th down' failure pretty much pushed them into the mainstream visibility, but footballcommentary.com has been around for a while, while Advanced NFL Stats is more recent.
The entire idea behind both of those websites is simple: you have a decision between two or more options - we'll stick with 2, and call them A and B. Figure out all possible outcomes of A, and average them. Figure out all possible outcomes of B, and average them. If A's average outcome is better than B's average outcome, choose A, otherwise choose B.
Pretty simple, huh?
One problem: it ignores the distribution of the outcomes of B and A - that is, it ignores the risk involved. All in all, the average expected value will tend to win out in the long run. But games, seasons, and coaches' careers aren't infinite - which means it's not really simple enough to ask "what's the best average expected outcome?" You really have to analyze the risk involved somehow.
Almost all of the 'decision questions' in football involve risky decisions vs. safe decisions. Should the coach go for it on 4th and 2 or punt? Punts are relatively safe - it's safe to simplify things and say that a punt is always better than a failed 4th down conversion.
That means that you have two choices: take a safe option (punting) and gain a little, or risk that to gain a lot.
Brian at AdvancedNFLStats basically puts it this way: going for it is a 60% chance of having a 100% chance to win the game, and a 40% chance of having a 53% chance of winning the game. Punting results in a 70% chance to win the game.
So, let's rescale things to make it more obvious, and subtract 53% (the lowest win chance) from all numbers. The question, then, is: "should I take a guaranteed 17% improvement in win probability, or go for a 60% chance at a 47% improvement?" Obviously the "expected value" choice is to go for it. However, look at the two positive outcomes: in one case, you win 100% of the time, and in the other case, you win 70% of the time. Those are both pretty good positions to be in. Now look at the negative outcome: you win with 53% chance. Basically a coin flip.
It's reasonable to believe that a coach might look at that and say "you know, winning 70% of the time and ~100% of the time aren't that different, but winning 53% of the time sucks." Let's put it a different way: winning 70% of the time gets you 11 wins, and good freaking chance you're in the playoffs. Winning 100% of the time? OK, you're obviously in the playoffs. Winning 53% of the time? 8 wins and you're going home.
What I'm suggesting is that coaches might view their improving odds with diminishing returns, and not see that much of a difference between 70% and 100%. Football is a low-scoring sport, with just a few high-leverage plays - taking the 'safe' decision too often isn't all that crazy.
The interesting thing - to me, at least - is that you could try to figure out exactly how coaches *do* view winning percentages. How valuable is it to a coach to move his winning percentage from 90% to 95%? What about from 50% to 55%? It's safe to say that even though they're equivalent changes, I doubt most coaches would care much about the former if there was much risk involved. Can we do this?
Easy - instead of starting off with the assumption that coaches don't know the percentages, and are simply making ill-informed decisions, assume that they *do* know the percentages, and try to find a function which rescales the winning percentages (u(WP%)) which makes the 'safe' decision better (i.e. the one they actually take).
That function - the u(WP%)? It's usually called a utility function.
As it turns out, it doesn't take a lot to do this. I'll show that in a future post, using Belichick's decision, which is pretty ideal for this.
Why so quiet?
OK, first off, I know I haven't posted anything here for a while. I'd like to say "!*^% you" to the world, because it seems like every time I start up a blog about something, just a few months in, poof! Some dramatic, huge, life-changing thing happens and I have to put things on hold for a while (I previously started up Bleed Blue 'n White, and note what happened to cause that change).
Then I never get back to it. This time, lo and behold, something again happened (again, family medical emergency, so if this is the last post here - well, second-to-last, because I'm planning another one right now), apparently, I up and died or something), and I'm forced to move a quarter of the way around the planet in two months. Yeah. Fun.
Then I never get back to it. This time, lo and behold, something again happened (again, family medical emergency, so if this is the last post here - well, second-to-last, because I'm planning another one right now), apparently, I up and died or something), and I'm forced to move a quarter of the way around the planet in two months. Yeah. Fun.
Sunday, January 10, 2010
Run/pass, continued
(note: axes labels in second plot are screwed up - it's actually "run fraction" and "pass D fraction")
The previous post gave a simple model for play sequencing that results in unequal run/pass payoffs, but that's not the only way for things to be complicated in play-calling. In the previous example, you've still got a stable Nash equilibrium, located at the minimax point of the two-play sequence. Given the variation we see in NFL playcalling, it seems unlikely that a stable Nash equilibrium exists at all - coaches almost seem to choose the fraction of times that they run based on personal preference, rather than some optimal mix.
Competition dynamics can provide more complicated behavior than a simple stable Nash equilibrium, however, but essentially require nonlinear behavior in the "utility function" - that is, the function that gives the payoff for a choice as a function of the opposing player's choice. One possibility is a fixed point which is unstable - that is, one of the players has incentive to move away - but which admits oscillations about that point. You see behavior like this with predator-prey dynamics.
Consider the following game:
This may seem very bizarre, but basically the idea is that as the various personnel see a certain type of play more, they react quicker to it rather than the other option. One note about this model is that things jitter around a lot early on (as the fractions jump around a lot) but then settle as the game goes on and approach an equilibrium behavior. I'll only talk about the equilibrium behavior.
Assume that the fraction of runs the offense attempts is x, and the fraction of pass Ds the defense attempts is y (yes, continuing my ridiculously silly column order mixup). As the number of plays gets large, the utility function for run and pass approach:
As you can see, the utility function is clearly non-linear, and moreover, depends on the offense's choice. Passing or running 100% of the time is a poor choice regardless of what the defense does : for a pass, the payoff is zero if the opponent plays run all the time, and -1.5 if the opponent plays pass all the time.
This model isn't quite as silly as the previous one - in my mind, it's just as viable a model for football as the simplistic zero-sum, constant payoff game. Even if the defense is in a pass formation or in pass personnel, if an opponent constantly runs similar plays at them, they'll get better at recognizing it and will perform better against it. Not as good as the proper formation would, but better.
However, the "optimal strategies" for this kind of a game are extremely different. One way to see this is to look at the average payoff per play, as a function of pass fraction and run D fraction. Here's the plot for the simple zero-sum game, with coefficients ((0.5,-1.5),(-0.5,1.5)).

I've compressed the scale and shifted it a bit to make it easier to see the main structure, which is that cross-shaped structure around (0.5,0.75). That's the minimax point, and the Nash equilibrium - note that at a run D fraction of 0.75, the defense has no incentive to change its playcalling, since the result is always the same. Similar for the offense at 0.5. And, as we expect, at these points, the payoffs for the two options are the same. Thus, the equilibrium is stable - if either player changes his strategy at this point, that player's payoff will decline or stay the same, and the other player will have a better strategy available as well.
But what about for our new "learning defense" game?

Wow, that looks completely different. There is something "kinda like" the equilibrium structure, at about (0.75, 0.75) here, but it's tilted almost 45 degrees. That is, past this point, "more passing/more run D" is strictly better for the offense, "more passing/less run D" is strictly better for the defense, and so forth. Note that this point is already weird - it's saying "run 75% of the time, but play pass defense 75% of the time."
This is not located at the minimax point for both players - the offense minimizes the defense's maximum payout at about ~60% running, whereas the defense minimizes the offense's maximum payout at about ~70% pass D.
That point is also not stable! At (0.75,0.75) the defense thinks it can do better by playing either run D more or pass D more. The offense thinks it's perfect. But when the defense plays, say, more run D, the offense can then improve by playing more pass. What you end up with are orbits around that point - in fact, if you model each team's behavior as "if you can do better, you try it" you get what's called a limit cycle, where defenses and offense continually chase each other's tail.
And that's the key to having unequal payoffs between runs/passes here: the "learning D" game model results in a situation where defenses always can do better, but offenses can always counter, and the method by which the two do better results in them oscillating over time between "run heavy/pass heavy." However, in this situation, over time, sometimes runs would be better, sometimes passes would be better - in a long term average, they would be somewhat close to equal. So the problem here may be that coaches aren't stupid, and over any small timeframe, passes and runs wouldn't be equal, but long term, things would somewhat balance out.
But! There's another equilibrium here, and it's stable: at roughly 90% passing, 10% running, with defense playing 100% run D (at 0.1, 0). The offense thinks it's doing the best it can, as does the defense for small changes - it can't see that if it played 40% run D (a huge change) it'd get the same results, and even less run D would give it even better results (pushing back to the limit cycle).
At this point, the run/pass payoffs aren't equal at all! Runs produce -1.1, and passes produce 0.25. Think about how insane this seems: the offense is passing 90% of the time, but you're playing 100% run defense - because it's 'good enough,' and playing the pass 'a little bit' makes things worse. From the offense's point of view, runs are god-awful, but mixing them in even a little boosts the output of your passing game a lot (from zero to 0.25 in this case).
Sounds like a plausible description of the current situation.
So now we have two ways that we can have unequal run/pass payoffs without stupid coaches:
In the second situation, there may be a better option available (the league could be 'stuck') but the coaches aren't being stupid, because the 'better option' doesn't really appear 'better' unless you drastically change; small changes just make things worse.
In this case, the game theorists could be both right and wrong; it may be that the current situation isn't ideal, but the league is trapped in a local optimum away from a global optimum.
The previous post gave a simple model for play sequencing that results in unequal run/pass payoffs, but that's not the only way for things to be complicated in play-calling. In the previous example, you've still got a stable Nash equilibrium, located at the minimax point of the two-play sequence. Given the variation we see in NFL playcalling, it seems unlikely that a stable Nash equilibrium exists at all - coaches almost seem to choose the fraction of times that they run based on personal preference, rather than some optimal mix.
Competition dynamics can provide more complicated behavior than a simple stable Nash equilibrium, however, but essentially require nonlinear behavior in the "utility function" - that is, the function that gives the payoff for a choice as a function of the opposing player's choice. One possibility is a fixed point which is unstable - that is, one of the players has incentive to move away - but which admits oscillations about that point. You see behavior like this with predator-prey dynamics.
A simple, non-linear model
Consider the following game:
- Each team chooses a number of plays, either run or pass.
- The plays are then presented, one against each other, randomly.
- The payoff for a run vs. run is -1-(number of previous run vs. run plays)/(number of previous plays)
- The payoff for a run vs. pass is 1-(number of previous run vs. pass plays)/(number of previous plays)
- The payoff for a pass vs. pass is -0.5-(number of previous pass vs. pass plays)/(number of previous plays)
- The payoff for a pass vs. run is 2.5-2.5*(number of previous pass vs. run plays)/(number of previous plays
This may seem very bizarre, but basically the idea is that as the various personnel see a certain type of play more, they react quicker to it rather than the other option. One note about this model is that things jitter around a lot early on (as the fractions jump around a lot) but then settle as the game goes on and approach an equilibrium behavior. I'll only talk about the equilibrium behavior.
Assume that the fraction of runs the offense attempts is x, and the fraction of pass Ds the defense attempts is y (yes, continuing my ridiculously silly column order mixup). As the number of plays gets large, the utility function for run and pass approach:
p(Run) = (-2x)y^2 + (2x+2)y - (1+x)p(Pass) = (3.5x-3.5)y^2 + (2-5x)y + 2.5xAs you can see, the utility function is clearly non-linear, and moreover, depends on the offense's choice. Passing or running 100% of the time is a poor choice regardless of what the defense does : for a pass, the payoff is zero if the opponent plays run all the time, and -1.5 if the opponent plays pass all the time.
This model isn't quite as silly as the previous one - in my mind, it's just as viable a model for football as the simplistic zero-sum, constant payoff game. Even if the defense is in a pass formation or in pass personnel, if an opponent constantly runs similar plays at them, they'll get better at recognizing it and will perform better against it. Not as good as the proper formation would, but better.
However, the "optimal strategies" for this kind of a game are extremely different. One way to see this is to look at the average payoff per play, as a function of pass fraction and run D fraction. Here's the plot for the simple zero-sum game, with coefficients ((0.5,-1.5),(-0.5,1.5)).

I've compressed the scale and shifted it a bit to make it easier to see the main structure, which is that cross-shaped structure around (0.5,0.75). That's the minimax point, and the Nash equilibrium - note that at a run D fraction of 0.75, the defense has no incentive to change its playcalling, since the result is always the same. Similar for the offense at 0.5. And, as we expect, at these points, the payoffs for the two options are the same. Thus, the equilibrium is stable - if either player changes his strategy at this point, that player's payoff will decline or stay the same, and the other player will have a better strategy available as well.
But what about for our new "learning defense" game?

Wow, that looks completely different. There is something "kinda like" the equilibrium structure, at about (0.75, 0.75) here, but it's tilted almost 45 degrees. That is, past this point, "more passing/more run D" is strictly better for the offense, "more passing/less run D" is strictly better for the defense, and so forth. Note that this point is already weird - it's saying "run 75% of the time, but play pass defense 75% of the time."
This is not located at the minimax point for both players - the offense minimizes the defense's maximum payout at about ~60% running, whereas the defense minimizes the offense's maximum payout at about ~70% pass D.
That point is also not stable! At (0.75,0.75) the defense thinks it can do better by playing either run D more or pass D more. The offense thinks it's perfect. But when the defense plays, say, more run D, the offense can then improve by playing more pass. What you end up with are orbits around that point - in fact, if you model each team's behavior as "if you can do better, you try it" you get what's called a limit cycle, where defenses and offense continually chase each other's tail.
And that's the key to having unequal payoffs between runs/passes here: the "learning D" game model results in a situation where defenses always can do better, but offenses can always counter, and the method by which the two do better results in them oscillating over time between "run heavy/pass heavy." However, in this situation, over time, sometimes runs would be better, sometimes passes would be better - in a long term average, they would be somewhat close to equal. So the problem here may be that coaches aren't stupid, and over any small timeframe, passes and runs wouldn't be equal, but long term, things would somewhat balance out.
But! There's another equilibrium here, and it's stable: at roughly 90% passing, 10% running, with defense playing 100% run D (at 0.1, 0). The offense thinks it's doing the best it can, as does the defense for small changes - it can't see that if it played 40% run D (a huge change) it'd get the same results, and even less run D would give it even better results (pushing back to the limit cycle).
At this point, the run/pass payoffs aren't equal at all! Runs produce -1.1, and passes produce 0.25. Think about how insane this seems: the offense is passing 90% of the time, but you're playing 100% run defense - because it's 'good enough,' and playing the pass 'a little bit' makes things worse. From the offense's point of view, runs are god-awful, but mixing them in even a little boosts the output of your passing game a lot (from zero to 0.25 in this case).
Sounds like a plausible description of the current situation.
So now we have two ways that we can have unequal run/pass payoffs without stupid coaches:
- Offenses may be optimizing multi-play sequences, rather than one play at a time.
- Defenses may play better when exposed to the same situations.
In the second situation, there may be a better option available (the league could be 'stuck') but the coaches aren't being stupid, because the 'better option' doesn't really appear 'better' unless you drastically change; small changes just make things worse.
In this case, the game theorists could be both right and wrong; it may be that the current situation isn't ideal, but the league is trapped in a local optimum away from a global optimum.
Thursday, January 7, 2010
Game theory and run/pass imbalance
There've been a few papers (here) and blogs (here) that have been investigating team playcalling - namely, the "run/pass" decision. The articles usually revolve around the fact that the run/pass payoffs are not equal. At face value, it seems like each play in football should be a zero-sum game - whatever the offense gains, the defense loses. And if each play is a zero-sum game, then, if the play calling is ideal, any grouping of plays you come up with should, on average, produce the same amount (assuming they were against an equal mix of defenses).
We observe that this isn't true: namely, passes produce significantly more than runs. Therefore, the conclusion they reach is that play calling is not ideal. This conclusion, however, isn't the only thing that could explain the observation.
Zero-sum games in general
The idea of a "zero-sum game" is that you've got two players, each of whom can make a choice - say, an offense choosing "run" or "pass," and a defense choosing "run D" or "pass D." The payoff for those choices is then summed up in a matrix:
These numbers are just arbitrary, of course. Von Neumann proved a theorem that says that the optimum strategy is for each player to randomly choose one of the choices, with a probability such that the combination minimizes the maximum payoff that your opponent can get (and thus maximizes your minimum payoff). At this optimum strategy, the payoffs of the two options are equal.
It's very hard to get around this final conclusion, as it's intuitively very simple: if runs produce so much less than passes, why not pass more? Then, the defense will play run D less, runs will produce more, and passes will produce less, and we'll all hit a nice equilibrium.
The thing is, we don't actually know what the payoff matrix is for football, of course. We just know what we see, and when we group passes together, we see one average payoff. When we group runs together, we see another average payoff.
Now consider this option: an offense chooses two choices, and presents them in whatever order they wish. The defense chooses two choices, but must randomly present them. If the offense chooses "run, run" or "pass, pass" the payoffs are the same as before. If they choose "run, pass" the payoffs for the second pass are drastically different (1, -1) - yes, good against a pass defense, and bad against a run defense (bear with me if this makes no sense). If they choose "pass, run" the payoffs for the second run are (0, -2).
The math for solving this is actually exactly the same as before, because both the choices on defense are independent of each other. The payoffs for each choice now depends on how often the defense plays 'run' or 'pass' so we can't write it in matrix form easily. We'll call the fraction of time that a defense plays 'pass' "pD%"
The solution, in this case, is for the defense to play pass D 69% of the time, and run D 31% of the time, and for the offense to choose "pass, pass" 50% of the time and "run, pass" 50% of the time.
But what's the payoff for runs alone? They're actually completely negative: -0.125, whereas passes are significantly more: 0.292. Note that both two play sequences do have equal payoff. The problem comes in not knowing that the "run" was required to set the defense up so that the second "pass" would work.
Edit: It's important to note that the entire reason this works is because the offense can sequence its playcalling, whereas the defense cannot. This may not make much sense, since as shown in the above table, a run is always followed by a pass - so it'd be pretty stupid to play the worse defense against a play that you know is coming.
So is this just an example of a stupid model? No, not really - because the two play sequence here does not have to be in order. The first play could be the first in the game, and the second could be 35 plays in. In that case, the defensive playcalling must be random because it has no idea when that (1,-1) pass will show up. For simplicity, we treat it here as a two-play sequence by the offense and random behavior by the defense.
A purist will note that I've essentially introduced two new "classes" of plays: the (1,-1) pass and the (0,-2) run. Why can't those be run on their own? That's because we're introducing the concept that the offense can manipulate the defense. (As an aside, it's easy to show that a R,P combination which is 'classical' run and 'classical' pass here is less preferable - it produces no net benefit versus any mixed strategy). The (1,-1) pass simply doesn't exist on its own.
Yeah, but does that game make any sense to model football?
That specific game? No, almost certainly not. But the question is "does it make sense to believe that plays can change the way a defense reacts to future plays?" and the answer to that is unquestionably yes. From here:
Moreover, the actions of a defensive player aren't entirely planned - they react to the offensive player, who already knows what he's going to do, for the most part. That reaction time is human, of course, and manipulating that reaction by play sequencing is completely believable. After all, I've watched Bugs Bunny.
But the basic point here is that the offense has an advantage in that it can choose what information a play will reveal. If a wide receiver is tired, they simply call a play to someone else. A defense has no fool-proof way to avoid a player being exposed without pulling him off the field.
Could this explain the excess runs, given their poor success? Probably. Runs are low-risk, and if you're running a play primarily to gain information or manipulate a defense, risk-minimization is probably what you want to do.
Same idea, different reasons
There's another possibility, too: what if running a play on offense changes the way the will perform? I don't need to cook up another game for this, as it's almost exactly the same. What if running a passing play reduces the effectiveness of the next passing play?
This possibility is more than plausible: a passing play, specifically, likely resulted in the wide receivers running 20-30 yards, and then quickly getting back to the line. Running another passing play would likely be much less effective - possibly completely ineffective - as the receivers could easily be exhausted. The offensive coordinator, knowing this, wouldn't be so silly as to run an additional pass.
Final thoughts
It's funny to read this conclusion from the Kovash & Levitt paper.
The fact that patterned play calling exists supports the idea that play sequence is important, and that plays are not sufficiently independent on their own.
One final thought: I'm not saying that it's not true that coaches should pass more. What I am saying is that I think the information imbalance between offense and defense makes any idea of a minimax solution to playcalling pointless. The comment in the Shanahan article stresses that.
We observe that this isn't true: namely, passes produce significantly more than runs. Therefore, the conclusion they reach is that play calling is not ideal. This conclusion, however, isn't the only thing that could explain the observation.
Zero-sum games in general
The idea of a "zero-sum game" is that you've got two players, each of whom can make a choice - say, an offense choosing "run" or "pass," and a defense choosing "run D" or "pass D." The payoff for those choices is then summed up in a matrix:
| Pass D | Run D | |
|---|---|---|
| Run | 0.5 | -1.5 |
| Pass | -0.5 | 1.5 |
These numbers are just arbitrary, of course. Von Neumann proved a theorem that says that the optimum strategy is for each player to randomly choose one of the choices, with a probability such that the combination minimizes the maximum payoff that your opponent can get (and thus maximizes your minimum payoff). At this optimum strategy, the payoffs of the two options are equal.
It's very hard to get around this final conclusion, as it's intuitively very simple: if runs produce so much less than passes, why not pass more? Then, the defense will play run D less, runs will produce more, and passes will produce less, and we'll all hit a nice equilibrium.
The thing is, we don't actually know what the payoff matrix is for football, of course. We just know what we see, and when we group passes together, we see one average payoff. When we group runs together, we see another average payoff.
Now consider this option: an offense chooses two choices, and presents them in whatever order they wish. The defense chooses two choices, but must randomly present them. If the offense chooses "run, run" or "pass, pass" the payoffs are the same as before. If they choose "run, pass" the payoffs for the second pass are drastically different (1, -1) - yes, good against a pass defense, and bad against a run defense (bear with me if this makes no sense). If they choose "pass, run" the payoffs for the second run are (0, -2).
The math for solving this is actually exactly the same as before, because both the choices on defense are independent of each other. The payoffs for each choice now depends on how often the defense plays 'run' or 'pass' so we can't write it in matrix form easily. We'll call the fraction of time that a defense plays 'pass' "pD%"
- Run, Run:
2*(0.5*pD% - 1.5*(1-pD%)) - Run,Pass:
(0.5*pD%-1.5*(1-pD%))+(1*pD%-(1-pD%)) - Pass,Pass:
2*(-0.5*pD% - 1.5*(1-pD%)) - Pass,Run:
(-0.5*pD%+1.5*(1-pD%))+(0*pD%-2*(1-pD%))
- Run,Run:
4*pD% - 3 - Run,Pass:
4*pD% - 2.5 - Pass,Pass:
-4*pD%+3 - Pass,Run:
-pD%-0.5
| Pass D | Run D | |
|---|---|---|
| RP | 1.5 | -2.5 |
| PP | -1 | 3 |
The solution, in this case, is for the defense to play pass D 69% of the time, and run D 31% of the time, and for the offense to choose "pass, pass" 50% of the time and "run, pass" 50% of the time.
But what's the payoff for runs alone? They're actually completely negative: -0.125, whereas passes are significantly more: 0.292. Note that both two play sequences do have equal payoff. The problem comes in not knowing that the "run" was required to set the defense up so that the second "pass" would work.
Edit: It's important to note that the entire reason this works is because the offense can sequence its playcalling, whereas the defense cannot. This may not make much sense, since as shown in the above table, a run is always followed by a pass - so it'd be pretty stupid to play the worse defense against a play that you know is coming.
So is this just an example of a stupid model? No, not really - because the two play sequence here does not have to be in order. The first play could be the first in the game, and the second could be 35 plays in. In that case, the defensive playcalling must be random because it has no idea when that (1,-1) pass will show up. For simplicity, we treat it here as a two-play sequence by the offense and random behavior by the defense.
A purist will note that I've essentially introduced two new "classes" of plays: the (1,-1) pass and the (0,-2) run. Why can't those be run on their own? That's because we're introducing the concept that the offense can manipulate the defense. (As an aside, it's easy to show that a R,P combination which is 'classical' run and 'classical' pass here is less preferable - it produces no net benefit versus any mixed strategy). The (1,-1) pass simply doesn't exist on its own.
Yeah, but does that game make any sense to model football?
That specific game? No, almost certainly not. But the question is "does it make sense to believe that plays can change the way a defense reacts to future plays?" and the answer to that is unquestionably yes. From here:
In fact, Schlereth said many were added to see how a defense would react to something the Broncos did, for example, putting four wide receivers on the field. Once the defense showed how it was going to handle such a situation, Shanahan would add plays accordingly.Offenses have a strong advantage over defenses: they choose the plays. A defense simply cannot get an offense to attempt a deep pass to a WR to find out if they need to slant a safety to his side. An offense, however, can run a play to see how a defense reacts - and the defense can't choose not to react. A corner can't simply ignore the WR running a fake go route that the offense inserted specifically to see how the WR gets off the line.
Moreover, the actions of a defensive player aren't entirely planned - they react to the offensive player, who already knows what he's going to do, for the most part. That reaction time is human, of course, and manipulating that reaction by play sequencing is completely believable. After all, I've watched Bugs Bunny.
But the basic point here is that the offense has an advantage in that it can choose what information a play will reveal. If a wide receiver is tired, they simply call a play to someone else. A defense has no fool-proof way to avoid a player being exposed without pulling him off the field.
Could this explain the excess runs, given their poor success? Probably. Runs are low-risk, and if you're running a play primarily to gain information or manipulate a defense, risk-minimization is probably what you want to do.
Same idea, different reasons
There's another possibility, too: what if running a play on offense changes the way the will perform? I don't need to cook up another game for this, as it's almost exactly the same. What if running a passing play reduces the effectiveness of the next passing play?
This possibility is more than plausible: a passing play, specifically, likely resulted in the wide receivers running 20-30 yards, and then quickly getting back to the line. Running another passing play would likely be much less effective - possibly completely ineffective - as the receivers could easily be exhausted. The offensive coordinator, knowing this, wouldn't be so silly as to run an additional pass.
Final thoughts
It's funny to read this conclusion from the Kovash & Levitt paper.
Kovash and Levitt then look at the order of plays, and again find patterns that minimax theory would not predict. Conditional on other factors, a team that has passed is 10 percentage points less likely to pass on the next play.
The fact that patterned play calling exists supports the idea that play sequence is important, and that plays are not sufficiently independent on their own.
One final thought: I'm not saying that it's not true that coaches should pass more. What I am saying is that I think the information imbalance between offense and defense makes any idea of a minimax solution to playcalling pointless. The comment in the Shanahan article stresses that.
Monday, January 4, 2010
Welcome, blah, blah
I needed somewhere to write up random observations and opinions about football and the growing field of football statistics, so here we are. I'm an Eagles fan, hence the "Eagles By The Numbers," but most of the stuff I post will be non-Eagles specific. It'll probably be also dry and boring. Whee.
I should also note that I don't have a ton of time to explore in detail certain problems, but part of the reason I'm creating this blog is because there are a lot of people whose opinions on football are built on seriously flawed notions of the game. The idea that running keeps your defense off the field. The idea that a team that doesn't score a lot of points must have a bad offense.
A lot of those are cliches, but even some of the nouveau footballthink ideas are built on flawed assumptions. The idea that coaches should be passing a ton more because the average payoff for a run is so much lower. The idea that coaches should go for it a lot more on 4th down.
It doesn't take a lot to discredit those ideas, since most of them are built on theoretical assumptions and you can quickly show that they're flawed. So that's what we're here for. Which means that this site will contain a lot of me criticizing other people. Which I'm sure will make me look whiny, but please keep in mind the point of the blog.
Other sites you should read:
Football Outsiders
Advanced NFL Stats
Pro-Football-Reference (specifically the blog)
I should also note that I don't have a ton of time to explore in detail certain problems, but part of the reason I'm creating this blog is because there are a lot of people whose opinions on football are built on seriously flawed notions of the game. The idea that running keeps your defense off the field. The idea that a team that doesn't score a lot of points must have a bad offense.
A lot of those are cliches, but even some of the nouveau footballthink ideas are built on flawed assumptions. The idea that coaches should be passing a ton more because the average payoff for a run is so much lower. The idea that coaches should go for it a lot more on 4th down.
It doesn't take a lot to discredit those ideas, since most of them are built on theoretical assumptions and you can quickly show that they're flawed. So that's what we're here for. Which means that this site will contain a lot of me criticizing other people. Which I'm sure will make me look whiny, but please keep in mind the point of the blog.
Other sites you should read:
Football Outsiders
Advanced NFL Stats
Pro-Football-Reference (specifically the blog)
Subscribe to:
Posts (Atom)