Average number of wins for all teams shut out in the first 3 quarters of Week 3 preseason game (since 2000): 5.9 (N=15).
Just sayin'.
Monday, August 30, 2010
Tuesday, August 3, 2010
Preseason predictions - how to judge them?
Sigh. Once again, I'm writing a post which is basically a long response to a post of Brian Burke's. I'm starting to feel kinda bad because I don't harbor any resentment to him (or, really anyone else related to football statistics - it's just something I do completely for fun, usually during lunch).
But I really have trouble letting something go when it's wrong. And I've seen this mistake countless places, so here we go. There's a post here where he tries to compare the Football Outsiders preseason predictions to the results, and concludes that they're worthless, based on the Mean Absolute Error and the RMS Error. He claims that they're in fact, worse than just totally guessing.
He might be right that they're totally worthless. I have no idea. But I do know that his method of comparing them - using the mean and RMS - isn't good enough to say that, because they give a distribution of expected results, and that distribution isn't Gaussian. Plus he's also just using the mean prediction, which isn't all the information provided.
In fact, it's possible for one prediction to be better than another, even with a worse mean and RMS error.
First, imagine a season played 10,000 times. That would lead to some distribution of team wins - they win 10 so many times, 9 so many times, 8 so many times, etc. Divide by 10,000, and you get something that could be thought of as a probability distribution. It's not really, because the teams' distributions aren't independent. But pretend. It's the same thing that you're doing with mean/RMS anyway.
Now suppose you predict what that team's results are going to be. That gives you a second distribution. You expect so many times they'll win 10, so many times they'll win 9, etc.
So what's the best way to compare those distributions? Look at the mean and RMS of both of them? If the distributions are Gaussian (or "normal"), yes - because a Gaussian probability distribution is fully described by its mean and RMS (which turn out to be, in math-speak, its two moments). If they're non-Gaussian? No, most definitely not. Instead, the best way is a Kolmogorov-Smirnov test, also called a K-S test.
To describe: imagine the "underlying probability distribution" looks like this. This is probability of winning X games, from 0-16.

That's a flat distribution - you're equally likely to win 0 as 8 as 16. It's violently non-Gaussian. It also has a mean of 8 wins, and an RMS of 4.62.
Now let's imagine a Koko the Monkey prediction - you just say "8" every single time. This has a mean of 8 wins, and an RMS distribution of zero. That, obviously, looks like this:

Those two distributions look absolutely nothing alike. But if I draw from the "true" distribution, and predict with the "monkey" distribution, I'll get a mean absolute error of 0.0, and an RMS error of 4.62.
Now, here's the kicker. If my prediction was the true distribution, and I just use the mean (which is 8), I'll get a mean absolute error of (drum roll) - 0.0, and an RMS error of 4.62.
The problem, here, is that we didn't take into account the fact that the monkey distribution was predicting that it'll always be 8. And that's clearly wrong. But you could easily say "but at least it's right about the mean," right?
Nope. Now imagine someone trying to predict things here. They do a bunch of tests, and (wrongly) conclude that there's some information, but for the most part it's random - so they predict that the true distribution is a Gaussian distribution, with a mean of 4, and a width of 32. This looks like this:

It probably looks essentially flat to you ; there's a slight, slight excess around 4, and there are more 0-7 than 9-16 predictions. This results in a mean of 7.8, which means that the mean absolute error, if you used this distribution to predict things, would be 0.2. The RMS error would be a bit bigger than 4.62 (but not much).
So this distribution has a worse mean absolute error, and a worse RMS error, than Koko the Monkey's prediction. And yet, it has a better K-S test statistic (significantly better) than Koko the Monkey's prediction. It is, in fact, a much better guess as to the underlying distribution than Koko the Monkey's guess.
But isn't Koko the Monkey's prediction better? It's better in both RMS error and absolute error, right? No, absolutely not. If someone told you team A will win 8 games, guaranteed, and you believed them, you'd bet on an over-under of 7 games, wouldn't you? What about if someone told you they're just about as likely to win less than 7 as more than 7? Then you wouldn't.
Comparing mathematical predictions for football is always a little tough, especially because you only get one shot at it, and really, all 32 teams have different factors involved. So you really want to look at the ability of a prediction system to predict, say, a team when it changes quarterbacks, or changes coaches, separately than when you're just predicting effects from high-leverage regression to the mean.
But just looking at mean absolute error and RMS error is really, really simplistic. What you really care about is comparing the prediction to the result. The predictions have some distribution, and the results have some distribution, so the best way to compare them is a K-S test.
But I really have trouble letting something go when it's wrong. And I've seen this mistake countless places, so here we go. There's a post here where he tries to compare the Football Outsiders preseason predictions to the results, and concludes that they're worthless, based on the Mean Absolute Error and the RMS Error. He claims that they're in fact, worse than just totally guessing.
He might be right that they're totally worthless. I have no idea. But I do know that his method of comparing them - using the mean and RMS - isn't good enough to say that, because they give a distribution of expected results, and that distribution isn't Gaussian. Plus he's also just using the mean prediction, which isn't all the information provided.
In fact, it's possible for one prediction to be better than another, even with a worse mean and RMS error.
First, imagine a season played 10,000 times. That would lead to some distribution of team wins - they win 10 so many times, 9 so many times, 8 so many times, etc. Divide by 10,000, and you get something that could be thought of as a probability distribution. It's not really, because the teams' distributions aren't independent. But pretend. It's the same thing that you're doing with mean/RMS anyway.
Now suppose you predict what that team's results are going to be. That gives you a second distribution. You expect so many times they'll win 10, so many times they'll win 9, etc.
So what's the best way to compare those distributions? Look at the mean and RMS of both of them? If the distributions are Gaussian (or "normal"), yes - because a Gaussian probability distribution is fully described by its mean and RMS (which turn out to be, in math-speak, its two moments). If they're non-Gaussian? No, most definitely not. Instead, the best way is a Kolmogorov-Smirnov test, also called a K-S test.
To describe: imagine the "underlying probability distribution" looks like this. This is probability of winning X games, from 0-16.
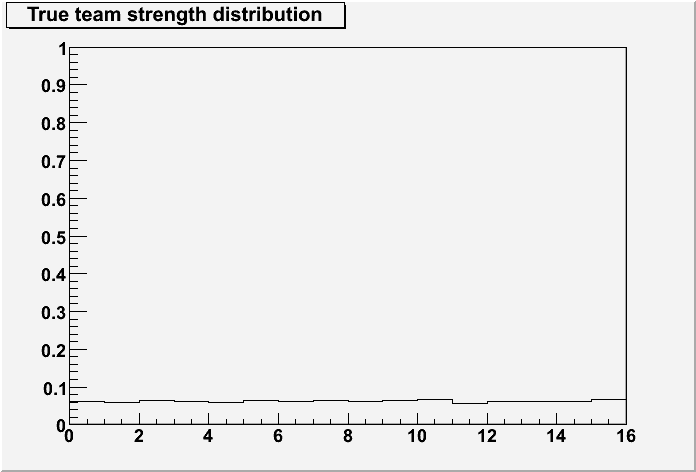
That's a flat distribution - you're equally likely to win 0 as 8 as 16. It's violently non-Gaussian. It also has a mean of 8 wins, and an RMS of 4.62.
Now let's imagine a Koko the Monkey prediction - you just say "8" every single time. This has a mean of 8 wins, and an RMS distribution of zero. That, obviously, looks like this:

Those two distributions look absolutely nothing alike. But if I draw from the "true" distribution, and predict with the "monkey" distribution, I'll get a mean absolute error of 0.0, and an RMS error of 4.62.
Now, here's the kicker. If my prediction was the true distribution, and I just use the mean (which is 8), I'll get a mean absolute error of (drum roll) - 0.0, and an RMS error of 4.62.
The problem, here, is that we didn't take into account the fact that the monkey distribution was predicting that it'll always be 8. And that's clearly wrong. But you could easily say "but at least it's right about the mean," right?
Nope. Now imagine someone trying to predict things here. They do a bunch of tests, and (wrongly) conclude that there's some information, but for the most part it's random - so they predict that the true distribution is a Gaussian distribution, with a mean of 4, and a width of 32. This looks like this:

It probably looks essentially flat to you ; there's a slight, slight excess around 4, and there are more 0-7 than 9-16 predictions. This results in a mean of 7.8, which means that the mean absolute error, if you used this distribution to predict things, would be 0.2. The RMS error would be a bit bigger than 4.62 (but not much).
So this distribution has a worse mean absolute error, and a worse RMS error, than Koko the Monkey's prediction. And yet, it has a better K-S test statistic (significantly better) than Koko the Monkey's prediction. It is, in fact, a much better guess as to the underlying distribution than Koko the Monkey's guess.
But isn't Koko the Monkey's prediction better? It's better in both RMS error and absolute error, right? No, absolutely not. If someone told you team A will win 8 games, guaranteed, and you believed them, you'd bet on an over-under of 7 games, wouldn't you? What about if someone told you they're just about as likely to win less than 7 as more than 7? Then you wouldn't.
Comparing mathematical predictions for football is always a little tough, especially because you only get one shot at it, and really, all 32 teams have different factors involved. So you really want to look at the ability of a prediction system to predict, say, a team when it changes quarterbacks, or changes coaches, separately than when you're just predicting effects from high-leverage regression to the mean.
But just looking at mean absolute error and RMS error is really, really simplistic. What you really care about is comparing the prediction to the result. The predictions have some distribution, and the results have some distribution, so the best way to compare them is a K-S test.
Subscribe to:
Posts (Atom)